econometrics | 计量经济学课程笔记

Stata代码
1 | reg y x |
1 绪论(2分的选择题)
- 成功三要素:理论、方法、数据
- 数据质量要求:完整性、准确性、可比性、一致性
2 一元线性回归
2.1 经典假设
(所有的经典假设都是针对总体而言的)——经典线性回归的假设
前4条为高斯-马尔可夫假设
(针对模型设定)假设1:回归模型是正确设定的。
- 满足则没有设定偏误
- 模型选择了正确的变量(既没有遗漏相关变量、没有多选无关的变量)、正确的函数形式
- 生产函数:幂函数(产出-资本投入、劳动投入)
(针对解释变量)假设2:解释变量X在简单随机抽样中具有变异性,而且随着样本容量的无限增加,解释变量X的样本方差依概率收敛于一非零的有限常数,即:
(针对随机干扰项的假设)假设3:给定解释变量X的任何值,随机干扰项
的均值为零。 (条件0均值) - 满足则
为外生解释变量/严格外生的,否则 为内生解释变量。 - 成立时
- 期望迭代法则推出->
- 随机干扰项和解释变量之间的不相关性:
【 是同期外生的, 与 同期不相关】
- 期望迭代法则推出->
(针对随机干扰项的假设)假设4:随机干扰项
具有给定X任何值条件下的同方差性及不序列相关性。 (针对随机干扰项的假设)假设5:随机干扰项服从零均值、同方差的正态分布
2.2 最小二乘法估计
- 参数估计的优劣
- 无偏性(期望值是否等于总体参数值)
- 有效性(是否在无偏估计量中具有最小方差性)
- 前两个准则:有限样本性质、小样本性质(不以样本的大小改变)
- 一致性(样本容量趋于无穷大,依概率收敛于总体真值)
- 无限样本性质、大样本渐进性质
- 大样本条件下只要求同期不相关,不要求条件零均值
- 大样本只要是通过简单随机抽样获得的,则无须随机干扰项的正态分布假设
- 无限样本性质、大样本渐进性质
- OLS(Ordinary Least Square)估计
- 两个正规方程组
- 小样本性质
- 线性性
- 无偏性
- 有效性
- 大样本性质
- 一致性
- 拟合优度检验
- TSS(总离差平方和)=ESS(回归平方和)+RSS(残差平方和)
2.2 统计检验
2.2.1 基础知识
在
是正态分布的假设下,以X为条件,Y呈现正态分布: 随机干扰项
的方差 的估计(都要记) (重点)
2.2.2 变量显著性检验
t检验
统计量:
统计量:
置信区间估计
的置信区间为 - 如何缩小置信区间
- 增大样本容量
- 提高模型拟合度(减小残差平方和)
- 增大样本容量
2.2.3 预测
样本估计值
是总体均值 和个别值 的无偏估计,可作为预测值(P47)
1. 总体条件均值预测值的置信区间
置信度下,总体均值 的置信区间为
2. 总体个别值预测值的置信区间
(记住) 置信度下,总体均值 的置信区间为
3. 总结
- 样本容量n越大,预测精度越高,反之预测精度越低。
- 样本容量一定时,置信带的宽度在X的均值处最小,在其附近进行插值预测精度高;X越远离均值,置信带越宽,置信度越宽,预测精度下降。
3 多元线性回归

3.1 基础知识
- 一般形式:
- 解释变量数目:k+1
- 非随机形式:
偏回归系数:单位变化 对 的平均响应
- 矩阵形式
- 样本回归函数及其随机形式
3.2 经典假设(基本假定)P57
- 假设1:模型是正确设定的
- 假设2:解释变量具有变异性,各
之间不存在严格的线性相关性(无完全多重共线性),而且随着样本容量的无限增加,解释变量的样本形成的矩阵 依概率收敛于一可逆的有限常矩阵Q - 假设3:随机干扰项具有条件零均值性
- 保证了无偏性
- 假设4:随机干扰项具有条件同方差及不序列相关性
- 假设5:随机干扰项满足正态分布
3.3 参数估计(尽量看书)P58
3.3.1 OLS估计:残差平方和最小
- 两个正规方程组
- 矩阵表达
- 离差形式
- 代入
可得
- 代入


3.3.2 矩估计(MM)▲
- 与最小二乘法估计完全等价
3.3.3 极大似然估计(ML)
- 从概率角度

3.3.4 拟合优度检验
- TSS(总离差平方和)=ESS(回归平方和)+RSS(残差平方和)
- 增加一个解释变量,
就会增加 - 调整的可决系数:
(可以小于0)
3.3.5 赤池信息准则和施瓦茨准则
- 不考统计量具体值
- 要求仅当所增加的解释变量能够减少AIC值或SC值才能在元模型中增加解释变量
3.4 统计性质
- 小样本性质
- 线性性
- 无偏性
- 有效性
- 大样本性质
- 一致性
- 渐近有效性
3.5 变量显著性检验
- 概率分布
- tj检验

3.6 方程显著性检验(F检验)
:全部参数为0(没有常数项) - 统计量:
与 方同方向变化
3.7 样本容量问题
- 样本容量不少于模型中解释变量的数目
- 满足基本要求的样本容量:
- 可考虑贝叶斯估计
- 大样本:
3.8 预测 P73
3.9 可化为线性的多元非线性回归模型
- 倒数模型、多项式模型、变量的直接置换法
- 幂函数、指数模型、函数变换法(C-D生产函数)
- 复杂函数模型与级数展开法
3.10 含有虚拟变量的多元线性回归模型P85
- 属性类型:取0或1
- 引入方式
- 加法方式:相同的斜率、不同的截距
- 乘法方式:只有斜率变化、截距和斜率同时变化
- 设置规则
- 每一定性变量所需的虚拟变量个数要比该定性变量的类别数少1
- m个定性变量,只在模型中引入m-1个虚拟变量
3.11 受约束回归P92的例题
3.11.1 模型参数的线性约束P91
- 受约束模型的残差平方和不小于无约束模型的残差平方和
- 对模型施加约束条件会降低模型的解释能力


3.11.2 对回归模型增加或减少解释变量
3.11.3 检验不同组之间回归函数的差异
3.11.4 邹氏稳定性检验
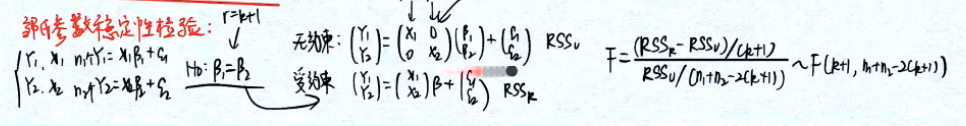
3.12 wald统计量▲

4 放宽假设的模型
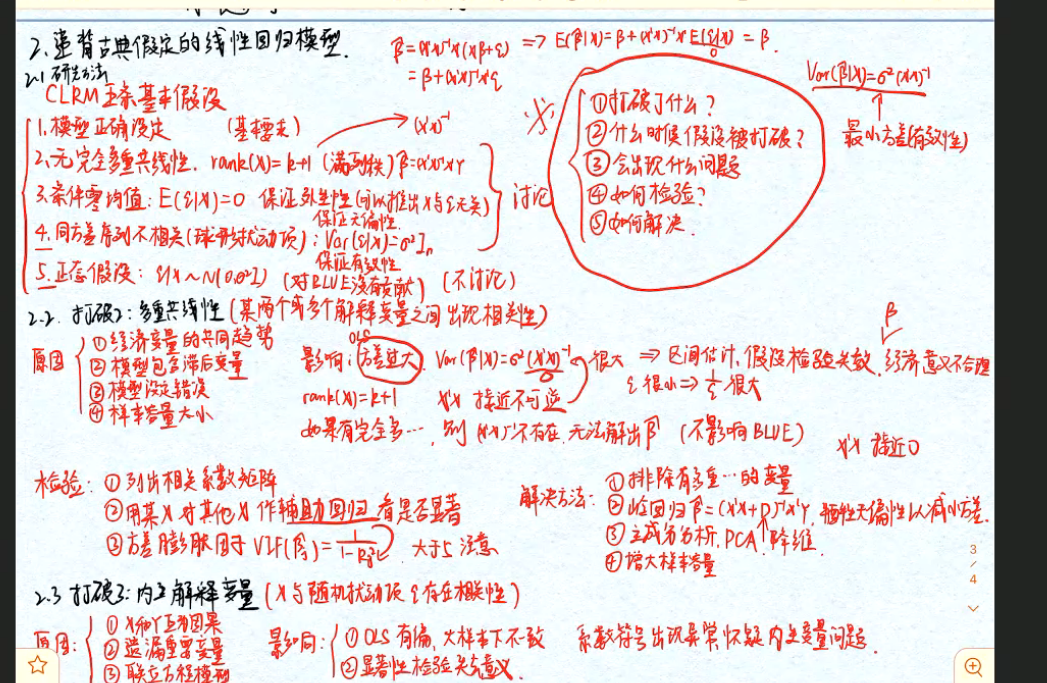
4.1 多重共线性
4.1.1 原因
- 经济变量相关的共同趋势
- 企业生产函数(相关性)
- 模型假定不谨慎
- 设定滞后变量
、设定错误
- 设定滞后变量
- 样本资料的限制(样本太少)
4.1.2 后果P107
- 完全共线性下参数估计量不存在
- 无法确定参数各自的估计
- 近似共线性下普通最小二乘估计量的方差变大
方差膨胀因子
当
0<VIF<5,没有共线性;当
5<VIF<10,弱复共线性;当
10<VIF<100,中等共线性;当
VIF>100,严重共线性。
- 参数估计量的经济学意义不合理
和 前的参数(不反映各自与解释变量之间的结构关系,而是反映它们对解释变量的共同影响)已经失去了应有的经济意义,于是经常表现出反常的现象,比如结果本应该是正的,结果却是负的。
- 变量的显著性检验模型的预测功能失去意义
- 存在多重共线性时,参数估计值的方差与标准差变大,从而容易使通过样本计算的t值小于临界值,误导作出参数为0的推断,将重要的解释变量排除在模型之外。
- 变大的方差容易使得预测区间变大,预测失去意义。
4.1.3 检验
- 检验多重共线性是否存在
- 求相关系数
- 综合统计检验法
与 值较大,但各参数估计值的 检验值较小。
- 求相关系数
- 估计多重共线性的范围
- 判定系数检验法P109
- 逐步回归法:逐个引入解释变量
- 如果拟合优度变化显著,则说明新引入的变量时一个独立解释变量
4.1.4 克服多重共线性的方法P109

- 排除引起共线性的变量
- 减小参数估计量的方差P110
- 注意事项
- 近似共线性:OLS估计量仍然是最佳线性无偏估计量;估计量的方差较大影响精度
- 多元回归中某几个解释变量相关性较强,不会影响与这几个变量无相关性的其他变量的参数估计的方差。
- 样本现象:增加样本容量
4.2 异方差性
- 对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同。
4.2.1 类型
- 同方差
- 异方差P115
- 单调递增型
- 单调递减型
- 复杂型
4.2.2 原因
- 样本观测值的观察误差随着解释变量观测值的不同而不同。如果样本观测值的观测误差构成随机误差项的主要部分,那么对不同的样本点,随机误差项的方差互不相同。(横截面数据中由于样本点存在个体差异)
- 不同样本点上解释变量以外的其他因素的差异较大,所以存在异方差性(遗漏重要解释变量)
4.2.3 后果
- 参数估计值是非有效的,大样本时不具备渐进有效性
- (不影响一致性或无偏性)
- 变量的显著性检验失去意义
- 模型预测失效,预测精度降低
4.2.4 检验:检验随机误差项的方差与解释变量观测值之间的相关性
- 图示检验法
散点图、 散点图进行判断 - BP检验 P116
estat hettest, rhs - white检验
estat imtest,white
4.2.5 异方差的修正
- 加权最小二乘法估计(WLS) P119
- 异方差稳健标准误法
4.3 内生解释变量问题

4.3.1 类型
- 内生解释变量与随机干扰项同期无关,但异期相关
- 内生解释变量与随机干扰项同期相关(截面数据)
4.3.2 原因
- 被解释变量与解释变量互为因果
- 模型设定时遗漏了重要的解释变量,所遗漏的变量与模型中一个或多个解释变量具有同期相关性
- 解释变量存在测量误差
4.3.3 后果
- 内生解释变量与随机干扰项正相关,容易出现X较小的点在总回归线下方,X较大的点的在总体回归线上方。
- 低估截距项,高估斜率项
- 参数估计量是有偏的,同时大样本下也是不一致的
4.3.4 工具变量法
- 满足条件(选取
作为内生解释变量 的工具变量) - 与所替代的内生解释变量高度相关:
- 与随机干扰项不相关:
- 与模型中其他解释变量不高度相关,以避免出现严重的多重共线性
- 与所替代的内生解释变量高度相关:
- 应用
- 为一致估计量 P131
- 两阶段的最小二乘估计:多个工具变量的情形
: 关于 的回归 - 以
为解释变量,进行
4.3.5 解释变量内生性检验
Hausman检验P132
4.3.6 过度识别约束检验(工具变量约束性)
- 如果寻找到的工具变量具有外生性,它们应与原模型中的随机干扰项不同期相关
- step1:对原模型进行两阶段的最小二乘回归
- step2:将记录的残差项再关于所有工具变量和原模型中的外生变量进行普通最小二乘回归
- step3:对该回归中所有工具变量前的参数都为0的假设进行联合性F检验
渐近分布为卡方分布(工具变量的个数必须多于内生变量的个数)
4.4 模型设定偏误问题P138
4.4.1 分类
- 关于解释变量选取的偏误(遗漏相关变量、多选无关变量)
- 关于模型函数形式选取的偏误
4.4.2 后果
- 遗漏相关变量偏误
- 漏掉的
与 相关,普通最小二乘法在小样本下是有偏的,在大样本下是非一致的。 与 同期相关,(正相关)X1的参数被高估,常数项被低估。 与 在给定样本下不正交, 满足无偏性与一致性, 是有偏和非一致的。 - 随机干扰项的方差估计也是有偏的
的方差是正确估计量 方差的有偏估计。(前者更小)
- 漏掉的
- 误选无关变量
- OLS估计量无偏,但不具备最小方差性(除非无关)【错误模型的方差一般会大于正常模型】
- 设定错误的函数形式
- 弹性(幂函数)与偏效应(线性)
4.4.3 检验
- 检验是否有无关变量
- t检验、F检验
- 检验是否有相关变量的遗漏或函数形式设定偏误
- 残差图示法(残差序列与解释变量的散点图)
- 先正、后负、再正,幂函数模型却选取了线性函数进行回归
- 一般性设定偏误检验
- 一般到简单(尽可能多选取)
- 检验X1的高次幂函数的显著性来判断是否将非线性模型误设
- 引入
的高次幂
- 残差图示法(残差序列与解释变量的散点图)

5 时间序列
5.1 序列相关性
5.1.1 定义
- 一阶序列相关性/自相关
, 为自协方差系数或一阶自相关系数(-1,1) 零均值、同方差、序列不相关
5.1.2 原因
- 经济变量固有的惯性
- 居民总消费除受总收入影响外,还受到其他因素的影响,例如消费习惯(正相关)
- 农产品的供给对价格的反映本身存在一个滞后期,t年的过度生产可能在t-1年削减产量
- 模型设定的偏误
- 遗漏解释变量或平方项——虚假序列相关
- 数据的“平滑”与编造
- 有数据通过已知数据生成、内插
5.1.3 后果
- 参数估计量非有效:一致但不有效
- 变量的显著性检验失去意义P152证明题练习
- 模型的预测失效
5.1.4 检验
- 图示法
与 与 - 回归检验法
- 以
为解释变量,如 等解释变量,建立各种方程,进行显著性检验
- 以
- D.W.检验量
- 假设条件
- 解释变量严格外生
- 随机误差项
为一阶自回归形式 - 回归模型中不应含有滞后被解释变量作为解释变量
- 回归模型含有截距项
- 原假设:
- 统计量:
- (0,
):正自相关 - (
):不能确定 - (
):无自相关 - (
):不能确定 :负自相关 - n较大时,
- 完全一阶自相关:
- 完全一阶负相关:
- 完全不相关:
- 完全一阶自相关:
- 只能检验一阶自相关,对存在滞后被解释变量的模型无法检验
- 假设条件
- 拉格朗日乘数检验法
- GB检验


5.1.5 补救 △
- 变换原模型为不存在序列相关的新模型(广义最小二乘法和广义差分法)P157
- 仍采用OLS估计,在对参数估计量的方差或标准差进行修正(序列相关稳健标准误法)
5.2 时间序列平稳性及其检验
5.2.1 理由
- 平稳性可以替代随机抽样假定
- 解释变量严格外生到解释变量同期外生
- 减少虚假回归——不存在因果
5.2.2 定义
- 假定某个时间序列是由某一随机过程生成的
- 满足条件
- 均值是是与时间t无关的常数
- 方差是与时间t无关的函数
- 协方差系数
是只与时间间隔 有关,与时间 无关的常数(趋于0) - 称该随机时间序列是宽平稳的或协方差平稳的。(稳随机序列或协方差随机序列)
- 平稳性类比截面数据的同分布概念
- 弱相关类比截面数据的独立性概念
- 白噪声
- 满足平稳、弱相关
- 随机游走
- 由如下随机过程生成
为一个白噪声,且与t期前的任何X不相关: - 一阶差分是平稳的
- 由如下随机过程生成
- 一阶回归过程
- 平稳 ——>对应的时间序列弱相关
5.2.3 平稳性的图示判断P168
5.2.4 平稳性的单位根检验P170(很重要)
检验 检验
5.2.5 单整时间序列
- 一次差分变平稳 为 1 阶单整
5.3 协整检验与误差修正模型
5.3.1 长期均衡关系与协整 P180
是 序列,则线性组合 是 序列,则变量 与 是协整的 - P181 推导
阶协整是一类非常重要的协整关系
5.3.2 协整性的检验
- 两变量的Engle-Granger检验
- step1:OLS估计方程并计算非均衡误差
——协整回归、静态回归 - step2:检验
的平稳性 - 检验平稳性采用DF检验或ADF检验
- 由于协整回归中已含有截距项,检验模型无须再用截距项
- 如果协整回归中还含有趋势项,则检验模型中也无须再用时间趋势项
- 使用模型1(原假设
)
- 估计量
往往是向下偏倚的,这样将导致零假设机会比实际情形大 - 协整ADF临界值
- step1:OLS估计方程并计算非均衡误差
- 多变量协整关系的检验
- 高阶单整变量的`Engle-Granger检验(没有成熟的临界值分布表)
5.3.3 均衡与协整关系的再讨论
- 差异
- 协整方程具有统计意义,均衡方程具有经济意义(必要不充分条件)
- 均衡方程中应该包含均衡系统中的所有时间序列,协整方程只包含一部分的时间序列
- 协整均衡方程只要求随机项是平稳的,而均衡方程要求随机项是白噪声。
5.3.4 误差修正模型
- 误差修正模型的含义
- 建立差分回归模型
- 检验是否存在静态均衡
DHSY模型P186
- 误差修正模型的建立
- 格兰杰表述模型P187
- EG两步法:
- 进行协整回归,检验变量间的协整关系,估计协整向量
- 若协整性存在,以第一步求得的残差作为非均衡误差项加入误差修正模型中,采用OLS估计相应参数
- 协整回归式中有趋势项,对残差项的检验就无须再设趋势项
- 第二步变量差分滞后项的多少,可以根据残差序列是否存在自相关性来判断
- 直接估计法
5.4 格兰杰因果关系检验
5.4.1 时间序列自回归模型
- 自回归模型
- AR(p)
- AR(p)模型的平稳性检验
- 引入滞后算子L
- 特征方程
5.4.2 自回归分布滞后模型
- 放松后的假设主要包括
是弱相关的平稳时间序列 - 模型中的各解释变量不存在完全的多重共线性
- 滞后阶数的选择
- 使模型随机干扰项不具有序列相关性
- 采用
AIC或SC准则
5.4.3 格兰杰因果关系检验及其应用
- 表述P191(重点)
- 实际应用中的几个问题
- 滞后期长度的选择问题:不同的滞后期得到不同的结果
- 时间序列平稳性问题
- 样本容量的问题:样本容量增大,格兰杰因果关系概率增大
- 格兰杰因果关系检验是必要性条件检验
5.4.4 向量自回归模型的讨论(脉冲响应分析和方差分解分析)
- 非结构化模型
- 预测相互联系的时间序列系统及分析随机干扰项对变量系统的动态冲击,从而解释各种经济冲击对经济变量形成的影响。
- 局限性
- 没有揭示经济系统中变量之间的直接因果关系
- 经济结构分析和政策评价劣势
- 经济预测方面,应用有条件
- 结构约束的影响
- Title: econometrics | 计量经济学课程笔记
- Author: Starry
- Created at : 2024-10-09 16:24:57
- Updated at : 2024-10-10 11:57:12
- Link: https://kilig1210.github.io/2024/10/09/计量经济学课程笔记/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments